
1. BIGGEST BOTTLENECK FOR AI MODEL DEVELOPMENT: DATA
AI model developments in general are often marked by a common pain point: the requirement for a large quantity of quality data. In the field of computer vision, this challenge is even more pronounced, as the acquisition of adequate visual data is often more time-consuming and more difficult than in other fields. Real-world datasets are typically unbalanced, with the distribution of relevant classes frequently skewed, leading to underrepresented classes and scenarios that models struggle to learn. These issues result in significant difficulties for computer vision engineers during data-driven development, as a comprehensive tool for all data-related tasks would be required.
The data problem in computer vision is addressed by DiffuseDrive [1], an automatic visual data service designed to provide meaningful insights into available data, identify data gaps, and fill those gaps with photorealistic, domain-specific, and labeled (both visual and textual) synthetic data. In this case study, the focus is on demonstrating the enhancement of precision, recall, and mAP metrics of an industry-standard object detection and classification model (YOLOv5 [2]). A fourfold improvement was achieved by utilizing DiffuseDrive visual data service on a real-world, aerial, unbalanced, and underrepresented dataset.
2. ASSESSMENT OF A REAL-WORLD DATASET FOR A COMPLEX USE-CASE
Computer vision developments often result in products that interact with the real-world. In many industries, the environment in which the computer vision enabled products are used, are controlled, like in a factory. However, in some industries, like autonomous driving, aerial autonomy (eg. drones) or industrial/civil/defense robotics, just to name a few, the environments can be complex, uncontrollable and dynamic. That is the reason why an aerial dataset was chosen as the subject of our study, because by achieving improvements in a model trained on such data, the results can be extrapolated to other industries, with more controlled environments as well.
For this case study, the open-source DOTA [3] dataset was picked. It contains classified bounding box labels for eighteen object classes. For the sake of easily digestible and quickly reproducible results, out of the eighteen classes, the focus of the study was on two: planes and helicopters.
Since the size of the images in the dataset are huge, and computer vision models preprocess such large images as smaller crops anyways, the original images got preprocessed to 600×600 pixels large crops. The condition for the cropping algorithm was to ensure that objects are within the created crops. This process yielded 2362 training and 599 validation images. Figure 1 demonstrates some example training images.

Figure 1: Example images from the real-world training dataset.
After the training and validation datasets were assembled, the object class distributions were examined. Figure 2 shows training, while Figure 3 shows the validation class distributions. It can be concluded that both the training and validation datasets are heavily unbalanced, with helicopters being significantly underrepresented. These histograms suggest that a detector model could be trained that is performing well on planes, but poorly on helicopters.
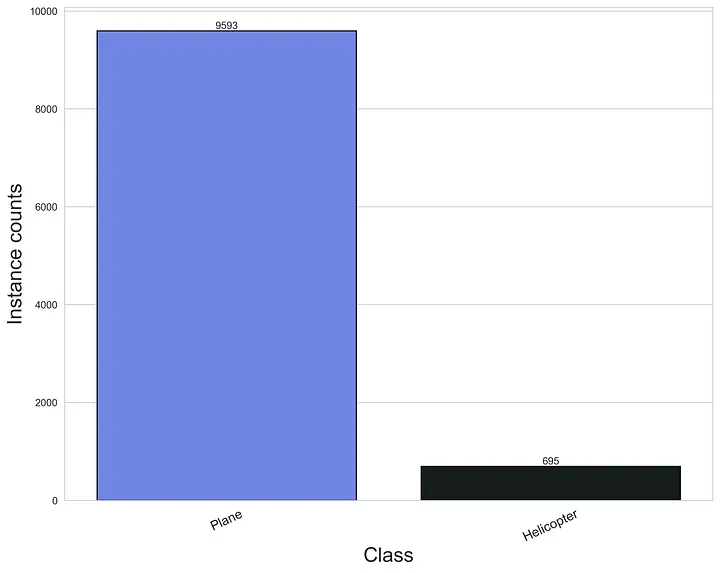
Figure 2: Class distribution of the real-world training dataset.
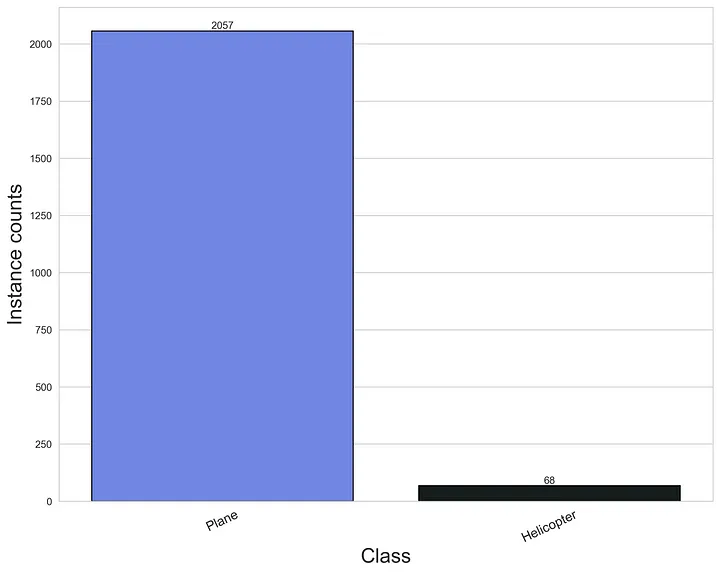
Figure 3: Class distribution of the real-world validation dataset.
Exploring a dataset which is already labeled can be a good starting point for a data-driven computer vision project. However, since images are unstructured data, labels, like bounding boxes only provide a limited amount of information. Getting more insights about unstructured data is a complex, non-trivial and tedious task. Solutions like DiffuseDrive’s Data Insights system can significantly shorten this process by yielding valuable information about the data at hand. It can identify data gaps according to the use-case. This is not the scope of this study, but as an important outlook, it was worth mentioning at this point.
3. CV MODEL PERFORMANCE ON REAL-WORLD DATA ONLY
The YOLOv5 [2] was the object detector model subject of this study, as it is one of the most well-known models in the computer vision community. Since transfer learning is a common practice in the field, the model weights were not randomly initialized. Instead, a pre-trained checkpoint [4] trained on the COCO dataset [5] was used, and transfer learning was performed on the full network for 100 epochs.
A fresh, random weight initialization was also tested. However, the results were comparable to those achieved with the pre-trained weights, and the training time was significantly longer. Therefore, the pre-trained weights were used for the final model training and evaluations.
Throughout the entire study, model validations were always performed on the same real-world validation dataset, as demonstrated in Figure 3, even though the training data was modified as the study progressed.
The evaluation metrics of the model trained on real-world data only are shown in Table 1 in Appendix A. As expected, the model achieves acceptable results for planes, but performs very poorly on helicopters.
In order to overcome the underrepresentation of helicopters in the real-world training dataset, DiffuseDrive visual data service was used to generate synthetic images.
4. SOLVING LAGGING PERFORMANCE WITH AI GENERATED SYNTHETIC DATA
Current data generation methods, such as rendering-based digital twins or previous generative models, such as GANs, are falling short of even adequate performance, let alone boosting CV performance noticeably. DiffuseDrive visual data service incorporates proprietary processes based on state-of-the-art generative AI practices on diffusion models and Low-Rank Adaptation (LoRA) [6] parameter efficient fine-tuning method to train in order to generate visual data that is indistinguishable from the data coming from the real world. For this study, as the underlying diffusion model, Stable Diffusion XL (SDXL) [7] was chosen. The main idea behind fine-tuning pre-trained diffusion models is to guide the model to generate imagery that is all in all photorealistic and indistinguishable from real-world images, yet controllable and consistent without artifacts and hallucinations that are present in pre-trained models.
With DiffuseDrive visual data service 2929 synthetic images were generated. Based on the previously discussed data exploration, the synthetic images were generated with a focus on helicopters, in order to achieve a more balanced dataset. From the 2929 generated synthetic images, some are shown on Figure 4.

Figure 4: Example synthetic generated images.
The generated synthetic images were then pseudo-labeled with a a state-of-the-art approach combining DINO [8], Detection Transformers (DETR) [9] and Grounded Language-Image Pretraining (GLIP) [10]. The class distribution of the synthetic dataset can be seen on Figure 5.
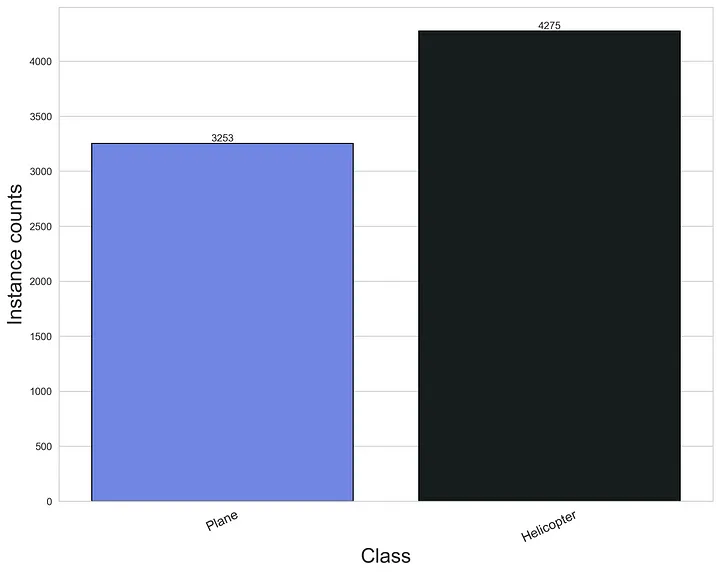
Figure 5: Class distribution of the synthetic dataset.
5. PERFORMANCE IMPROVEMENT EVALUATION ON SYNTHETIC DATA ONLY
The previously discussed YOLOv5 training procedure was repeated, but this time, for the training, only the generated synthetic images were used as the training set, and then evaluated on the same real-world validation dataset as before. The evaluation metrics of the model trained on synthetic data only are shown in Table 2 in Appendix A.
As it can be seen the overall results are significantly better than the ones achieved by real-world training dataset only (which were shown in Table 1). The performance on helicopters already surpassed the real-world-only training by 2–3 times.
However, it is worth mentioning that the recall and mAP values are slightly lower for airplanes but the precision is still higher. It goes without saying that this behavior was expected, because the synthetic-only dataset consisted just merely one third airplane objects than the real-world dataset. Still, it is remarkable that the model achieved comparable results by training with two thirds less synthetically generated airplane objects. These results are already a clear indication that the synthetic data was adequate to fill the data gaps in the real-world dataset as the model performed significantly better on helicopters.
Even though these results were promising, several combinations of synthetic data with the real-world data were planned, to see if the model’s performance can be further improved.
6. PERFORMANCE BOOM ON SYNTHETIC DATA COMBINED WITH REAL-WORLD DATA
The evaluation metrics of the models trained with different combinations of synthetic and real-world data are shown in Tables 3, 4, 5, 6, 7 and 8 in Appendix A. The exact number of synthetic and real-world images used for the different training combinations are shown in the table captions. As before, the validation data was always the same real-world validation dataset.
The evaluation metrics are also visualized for each training configuration in Figures 7, 8, 9, and 10 in Appendix B. In these figures, each training configuration is represented by a group of three bars corresponding to the ‘All’, ‘Plane’, and ‘Helicopter’ classes. The bar charts display Precision, Recall, mAP@.5, and mAP@.5:.95, respectively. The relative percentage change compared to the real-world-only baseline is annotated above each bar, indicating the performance improvement or decline for each class. These visualizations provide a clear comparison of the models’ performance across different training configurations, highlighting the significant enhancements achieved by combining synthetic and real-world data.
Based on the results, it can be concluded that the models’ performance dramatically improved with the combination of synthetic and real-world data. In the majority of cases, the metrics are remarkably four times better, and the models even performed better on airplanes than when trained with real-world-only data.
7. SUMMARY OF THE RESULTS
By a factor of 4, the metrics of YOLOv5 object detection model were improved in a real-world aerial, unbalanced and underrepresented object detection task. These outstanding results were achieved by utilizing DiffuseDrive visual data service to generate synthetic data to improve an object detection model. It can be concluded that even the synthetic-only data is at least equivalent, if not better, than the real-world-only data, even when used in comparably smaller quantities. As the generated data was high-fidelity, photorealistic and indistinguishable from the real-world data, it was able to fill the data gaps present in the real-world dataset.
8. OUTLOOK AND FURTHER APPLICATIONS
A computer vision development project is an iterative process, due to the data acquisition and utilization at different stages of the project lifecycle. In this case study, a reduced-scope results were showcased by generating synthetic data for selected classes. In real-world projects, the data generation process would not stop at this point as the development scope can always be expanded, establishing ideal dataset composition for the given use-case, addressing further classes, the correlation of features, introduction of further edge-cases, including more complex annotations and eventually expanding the scope and the complexity of the given use-case. This customer journey is visualized on Figure 6.
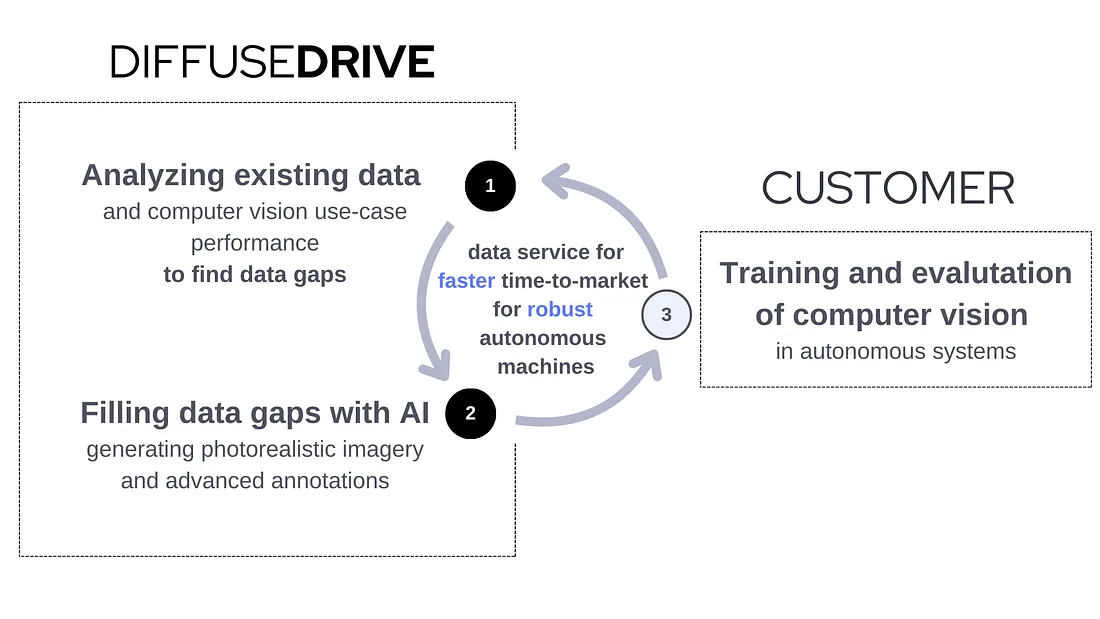
Figure 6: Customer journey with DiffuseDrive visual data service.
With all these being said, DiffuseDrive visual data service can significantly reduce the time-to-market for any computer vision project while also drastically increasing the robustness of the models.
Reach out to DiffuseDrive to see how it can be applied to your specific use case, and how it can help you to develop robust computer vision models faster.
9. APPENDIX A: DETAILED EVALUATION METRICS
As already stated in Section 3, throughout the entire study, model validations were consistently performed on the same real-world validation dataset, as demonstrated in Figure 3 in the main text, even though the training data was modified as the study progressed. This ensures that the evaluation metrics presented here accurately reflect the impact of different training data combinations on model performance.

Table 1: YOLOv5, training data: real-world-only, validation data: real-world-only.

Table 2: YOLOv5, training data: synthetic only, validation data: real-world-only.

Table 3: YOLOv5, training data: all synthetic combined with all real-world. Synthetic/Real-world data ratio: 1.24:1.

Table 4: YOLOv5, training data: 2693 synthetic combined with all real-world. Synthetic/Real-world data ratio: 1.14:1.

Table 5: YOLOv5, training data: 2457 synthetic combined with all real-world. Synthetic/Real-world data ratio: 1.04:1.

Table 6: YOLOv5, training data: 1985 synthetic combined with all real-world. Synthetic/Real-world data ratio: 0.84:1.

Table 7: YOLOv5, training data: 1512 synthetic combined with all real-world. Synthetic/Real-world data ratio: 0.64:1.

Table 8: YOLOv5, training data: 1040 synthetic combined with all real-world. Synthetic/Real-world data ratio: 0.44:1.
10. APPENDIX B: COMPARATIVE FIGURES AND VISUALIZATIONS
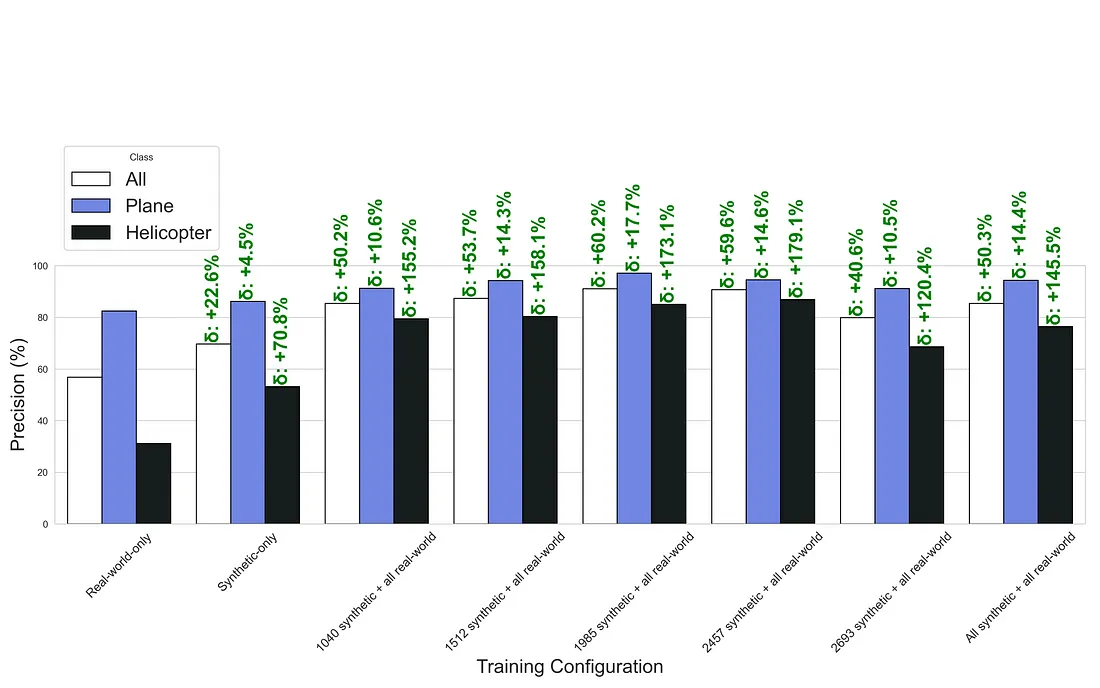
Figure 7: Precision comparison of the models trained with different data combinations.
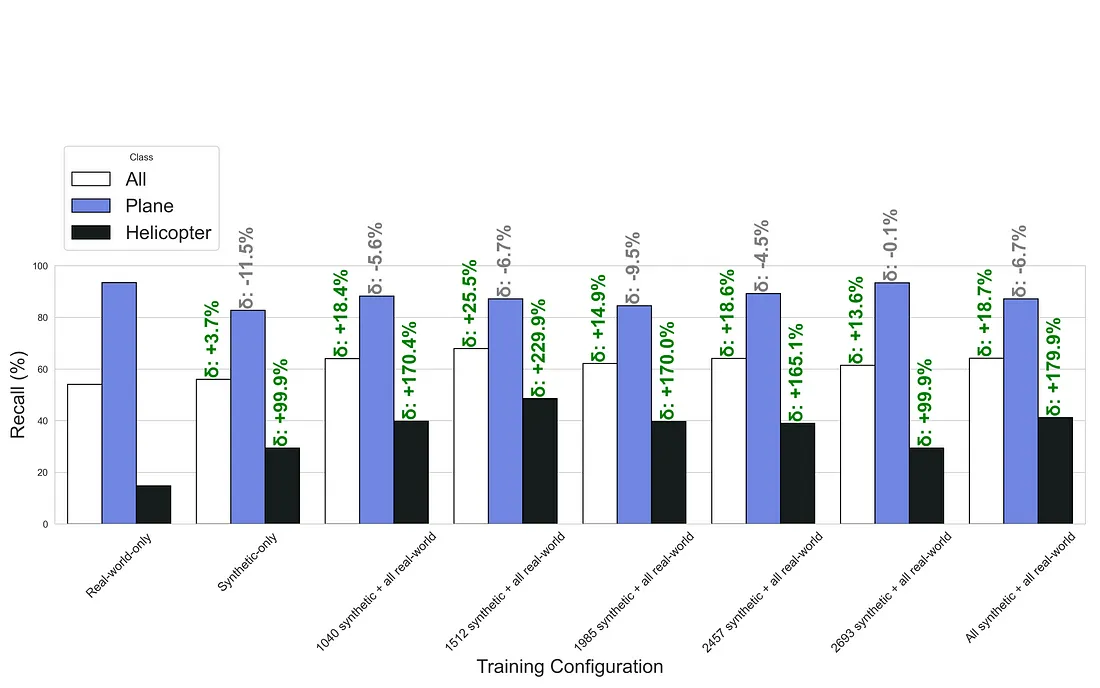
Figure 8: Recall comparison of the models trained with different data combinations.
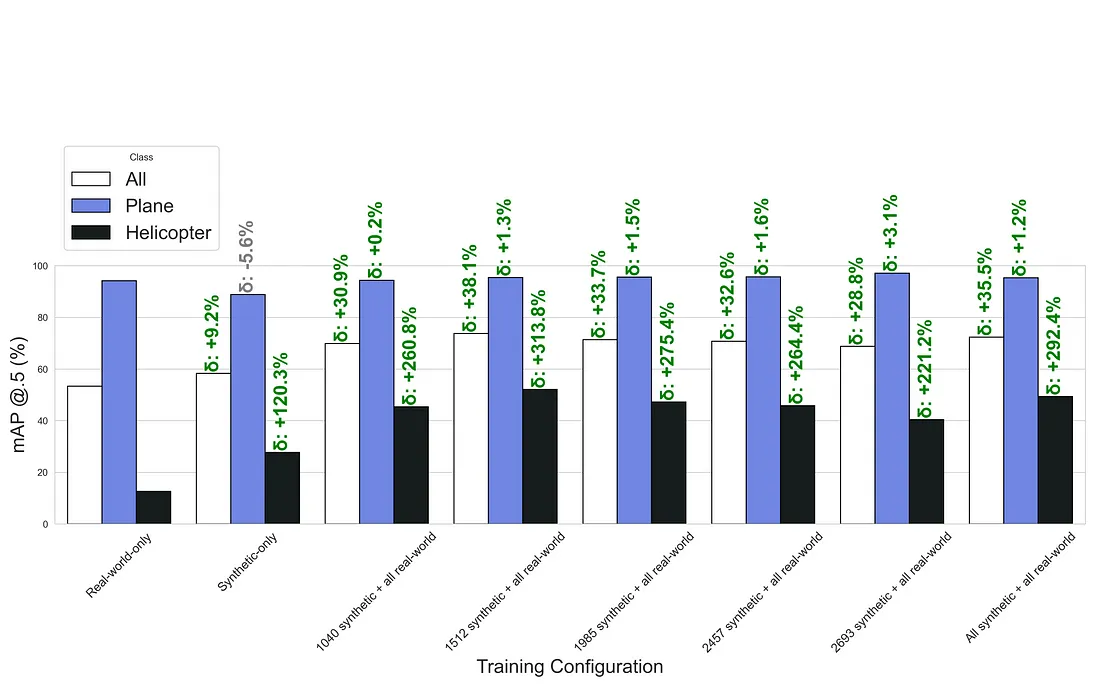
Figure 9: mAP @.5 comparison of the models trained with different data combinations.
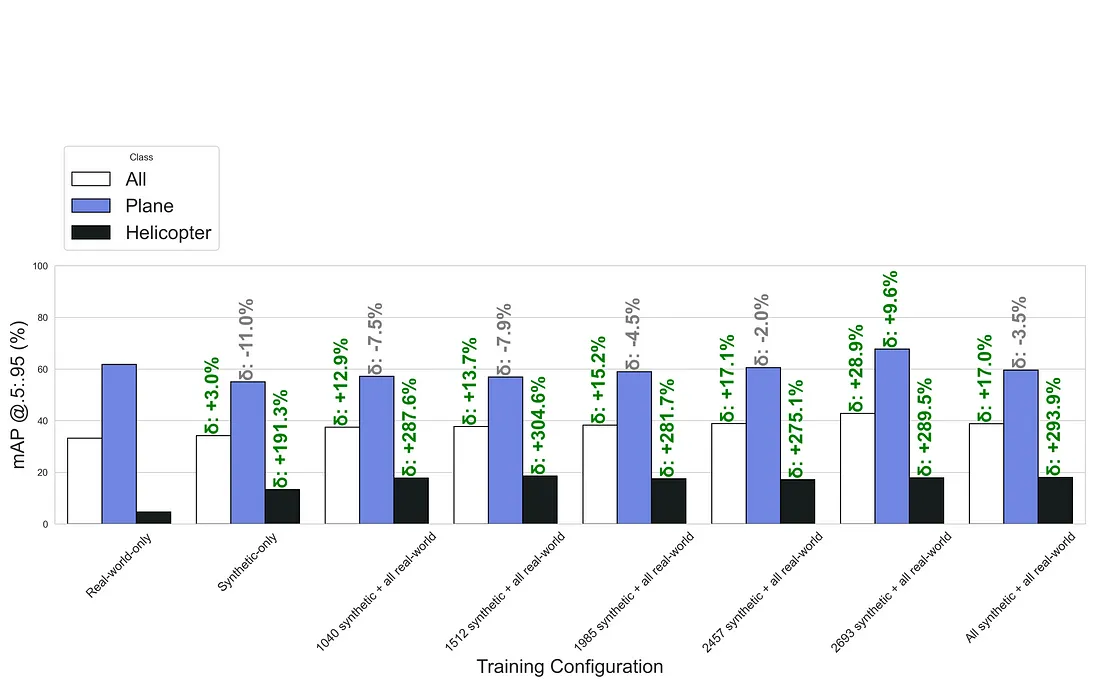
Figure 10: mAP @.5:.95 comparison of the models trained with different data combinations.
11. REFERENCES
[1] DiffuseDrive Inc., https://diffusedrive.com
[2] G. Jocher, Yolov5 by ultralytics, 2020.
[3] Dota dataset, https://captain-whu.github.io/DOTA/dataset.html.
[4] YOLOv5 coco pretrained weights, https://pytorch.org/hub/ultralytics_yolov5/.
[5] COCO dataset, https://cocodataset.org/#home.
[6] E. J. Hu et al., CoRR abs/2106.09685 (2021), 2106.09685.
[7] D. Podell et al., Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023, 2307.01952.
[8] M. Caron et al., CoRR abs/2104.14294 (2021), 2104.14294.
[9] N. Carion et al., CoRR abs/2005.12872 (2020), 2005.12872.
[10] L. H. Li et al., CoRR abs/2112.03857 (2021), 2112.03857.
Our Works
MORE Articles
A curated selection of deep dives, case studies, and practical knowledge to help you understand, adopt, and scale AI the right way.


